Finding Arozarena
You remember sorting baseball cards, right? You sorted them on anything; career stats, teams, season, jersey color. You got your sticky fingers all over those glossy, fresh pieces of thin cardboard and you just sorted away. Let’s think of a clustering algorithm called k-means clustering as that 8-year-old card sorter, only with a set of instructions. “Hey kid, here’s a bunch of cards from the last month of the season, back in 2020. Rather than your typical stat-lines, these cards show each player’s change in batted-ball and plate discipline from the first half of the month to the second half of the month. Here, take a look at Randy Arozarena”:
| First half of September: | Second half of September: | Diff: | |
|---|---|---|---|
| GB/FB rate | 2 | 1 | -1 |
| LD% | 11.80% | 21.70% | +9.9% |
| Z-Swing% | 61.40% | 70% | +8.6 |
“Now listen kid, I want to find a 2021 player like 2020 Arozarena. I need you to sort all these cards based on the change in GB% and change in Z-Swing%. Ok? Got that? Are you even listening to me!?”
Let’s replace the card-sorting kid with a computer and the baseball cards with publicly available FanGraphs data, but keep the concept the same. Let’s also have a goal in mind, find a player from the end of season 2021 that looked similar to the end of season 2020 Randy Arozarena. Why? Well, he was really good in the playoffs and no one really saw it coming and this is just kind of what we do.
Rather than telling the kid how many groups and what to sort them on, I’ll take over and do it with a clustering algorithm. I took all 2020 players with at least 20 PA’s in the first half of September and with at least 20 PA’s in the second half of September and calculated their difference in batted-ball and plate-discipline statistics during that time. Then, I built out the clustering model to sort those players into four groups based on GB%, to account for lifting the ball more, and Z-Swing%. Here’s the output:

We now have clusters of hitters who either started hitting the ball on the ground more often or less often as September went on and became more or less aggressive. Now, let’s look at data from 2021, structured in the same way and passed through the sorter that we created. Let’s also limit the data to 2021 postseason players:
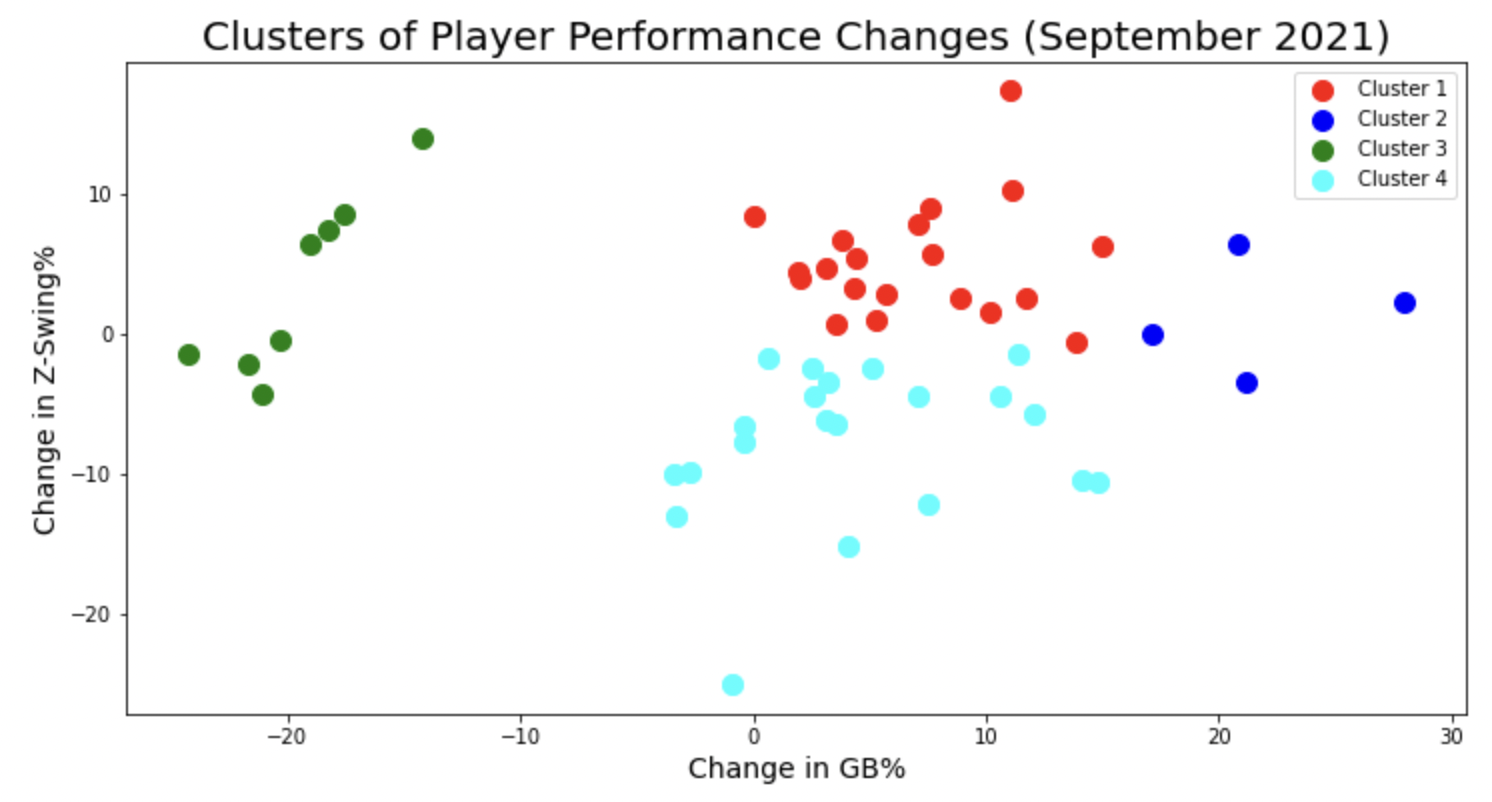
Pre-2020 postseason Arozarena was placed in cluster 3, or the dark green group. He had a big increase in his ability to lift the ball and he became more aggressive in the strike zone in the lead up to the 2020 playoffs. Who from the end of the 2021 season was placed in that same group? Here are the 2021 players categorized or sorted into the 2020 Arozarena cluster, cluster 3:
| Name | GB%_diff | Z-Swing%_diff |
|---|---|---|
| Paul Goldschmidt | -20.3 | -0.4 |
| J.D. Martinez | -18.3 | 7.4 |
| Tommy La Stella | -24.3 | -1.4 |
| Will Smith | -21.7 | -2.2 |
| Gleyber Torres | -21.1 | -4.3 |
| Tommy Edman | -17.6 | 8.5 |
| Austin Riley | -19.0 | 6.4 |
| Eloy Jiménez | -14.2 | 14.0 |
Half of these players are similar to last year’s Arozarena in their increased aggressiveness, but all of them have decreased their groundball rates going into the playoffs. Did we find this year’s Arozarena? Time will tell.
There were all kinds of ways to sort your baseball cards when you were a kid. There are all kinds of ways to sort players based on their stats. Finding two, very specific, statistics to focus on in an attempt to predict playoff performance might not be the best way to go about things. But, it does show how quickly we can find commonalities in player performance in short spans of time. One thing I would like to work on this offseason is looking for indicators that may help us predict those, seemingly random, spurts of production. Think of Marcus Semien’s May or Kyle Schwarber’s June. It sure would be nice to predict those clusters of performance ahead of time, particularly in shallow, daily lineup leagues. For now, clustering and sorting on snapshots of time is where I’ll start and it’s nice to have a few specific players to pay close attention to as the playoffs kick-off.
Interesting article, nice work